Using Docker and Kubernetes to produce a scalable fraud detection API
Summary. In this report a simple logistic regression model is used to classify credit card transactions as fraudulent or not. A Recall of \( \approx \) 0.8 and Precision of \( \approx \) 0.7 is obtained for a false positive rate of \( \approx \) 5x10 \( ^{-4} \). However, for a model to be useful from a business perspective an understanding of how to deploy the model in the real world is important. Docker and Kubernetes are investigated for this purpose.
Skills used:
- Model development (Python: NumPy, pandas and sklearn libraries).
- Web server software (Nginx, Flask)
- User Interface development (React.js, Node.js, Spring)
- Containerization software (Docker)
- Container deployment (Kubernetes)
Introduction
This project is based on the work done by Rinor Maloku in his excellent blog [1]. He outlines the steps of running a Python application which takes input from a user typed into a browser, processing that and returning an output which is then presented to the user in their browser. He then goes on to consider how to scale the problem to many users using Docker and Kubernetes.
In essense the aim of this project is very similar, although the problem the Python application is tasked with, is deciding whether or not the supplied information was derived from a fraudulent credit card transaction. In this way the idea of a scalable method for identifying fraudulent credit card transactions is investigated.
The project is divided into the following sections:
- Using Nginx web server to serve a React.js user interface.
- Handling front-end requests using Spring.
- Using sklearn to build a fraud detection model.
- Containerizing the model with docker.
- Scaling the model with Kubernetes.
Using Nginx web server to serve a React.js user interface
With Node.js [2] and NPM [3] installed, all the Java dependancies (defined in file package.json) required by the React.js [4] application (/src/app.js) are installed with 'npm install' which places them in the folder /node_modules. The application can be started with 'nvm start' which is then accessible at localhost:3000. At this point the App.js and index.html files were modified so that the web interface presented to the user be more suitable, as shown in Figure 1.
Figure 1: Modified API interface.
To build the React.js application into static files, able to be served using a web server, the command 'npm run build' is used to generate the static files in the folder /build. After installing Nginx [5], the contents of the build folder is placed in the correct /html folder such that the default index.html file Nginx serves is accesible (default on Ubuntu is /var/www/html). It should be available at localhost:80.
The React app performs the following steps:
- sets the url at which a POST call is made - where an application should be listening to process the request.
- retrieves the input text that is sent to the Python application.
- if a suitable response is retrieved display this in the desired format.
Handling front-end requests using Spring
The Spring [6] web application requires JDK8 [7] and Maven [8] be installed. 'mvn install' will create a folder called /target inside which the web application is packaged as a .jar. This can be started from the target directory with 'java -jar sentiment-analysis-web-0.0.1-SNAPSHOT.jar --sa.logic.api.url=http://localhost:5000' which also defines where to forward the information from the front-end.
Using sklearn to build a fraud detection model
scikit-learn [9] was used to develop a simple logistic regression model for the credit card data [10]. The data consists of information about credit card transactions made in Sep 2013. It contains the original features time and amount. All of the other 28 features have been anonymised using Principle Component Analysis. A further feature, class, is the response variable (1 if fraud, 0 if not). Of over 280 thousand transactions listed only 492 are classed as fraudulent and as such the dataset is highly unbalanced.
There are several approaches to dealing with data in which data from the different classes is highly unbalanced.
- Obtaining more data (impractical in this scenario).
- Oversampling the data (adding copies of the under represented class).
- Undersampling the data (reducing the amount of data for the over represented class to bring this in line with the number in the under represented class).
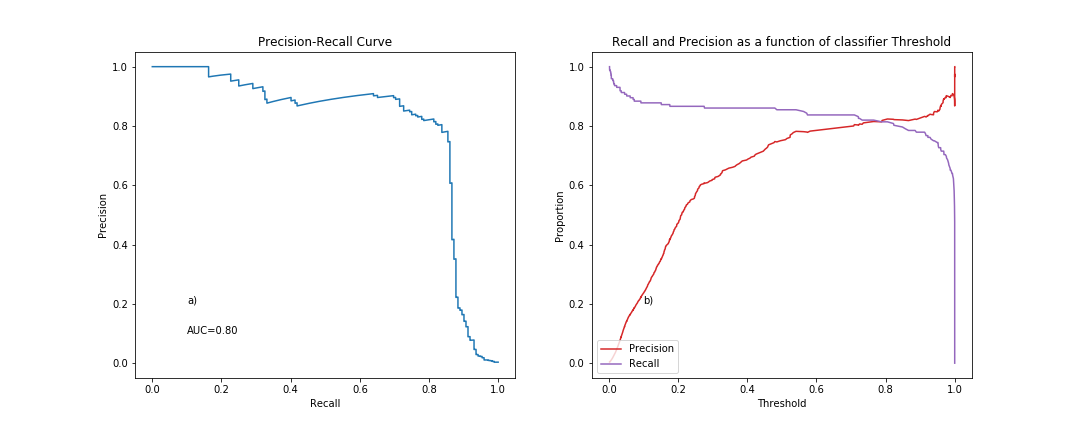
Figure 2: Plots showing a) precision vs recall and b) recall and precision as a function of threshold.
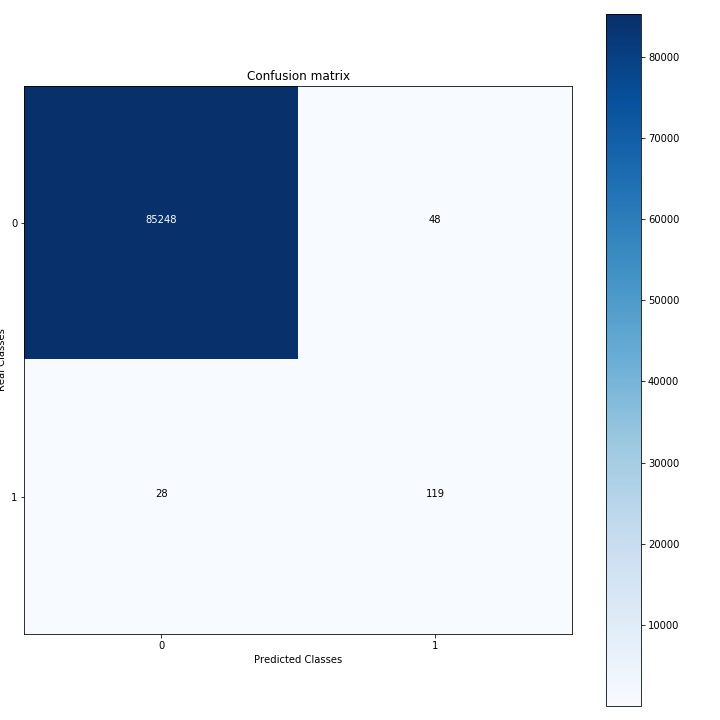
The resulting confusion matrix showing total number of events in each category (i.e. not normalised so the unbalanced nature of the dataset is not accounted for) is shown in Figure 3.
Figure 3: Confusion matrix associated with recall and precision of approximately 0.8.
As always there is a tradeoff to be made between Recall, Precision and Fallout, in particular, maintaining high Recall and Precision whilst minimizing Fallout. This could be set by the needs of the business. For example, in the case that the business has a high tolerance of the costs associated with assigning a non fraud as a fraud (false positive), then a higher Recall can be achieved.
The model was serealised using the Python pickle module, which is commonly used to enable models to be stored for later use. In this case the model is deserealised in the python application. The python application also does the following:
- using Flask, listens for requests on 0.0.0.0:5000. Defines the path at which a POST request can be made.
- extracts the user input (json) and puts this into a Dataframe.
- Loads the model and applies it to the Dataframe.
- Returns the response.
Containerizing the model with docker
Docker [11] containers enable a piece of software to be run on any system or machine, regardless of environment etc. The main advantages of docker containers are that they:
- are resource efficient (no virtual machines).
- are platform independent.
- simplify requirements using base images.
The front-end
The Nginx software is provided with a base image for Docker. This means that once the base image is defined, the only remaining step is to copy the contents of the build directory to the /usr/share/nginx/html directory in the image (as documented in the Nginx image documentation).
To build the docker container so its accessible in the local Docker image registry, the command is just
docker build -t APP_NAME .
Alternatively Docker Hub, a cloud container service, can be used. This requires a Docker account. The steps are:
docker login -u="$DOCKER_USERNAME" -p="$DOCKER_PASSWORD"
docker build -f Dockerfile -t $DOCKER_USER_ID/APP_NAME .
docker push $DOCKER_USER_ID/APP_NAME
docker pull $DOCKER_USER_ID/APP_NAME
To run the container
docker run -d -p 80:80 $DOCKER_USER_ID/APP_NAME
docker run -p 80:80 APP_NAME
80:80 is used to map the port on the host to the container port. A .dockerignore file can be included to speed up build time of containers, by specifying folders not to process.
The web and Python applications
In the web applications dockerfile two other variables must be defined
ENV SA_LOGIC_API_URL http://localhost:5000
EXPOSE 8080
The first defines an environment variable inside the container, allowing the url for the fraud detection API to be provided. The second reminds the user that 80:80 will be used subsequently. The dockerfile for the Python application is
FROM ubuntu:latest
RUN apt-get update -y && \
apt-get install -y python3-pip python-dev build-essential
COPY sa /app
WORKDIR /app
RUN pip3 install -r requirements.txt
EXPOSE 5000
ENTRYPOINT ["python3"]
CMD ["python_app.py"]
Following a similar procedure as before, the containers for the web and Python applications can be built. In order to run the full application from the docker images it is important that the ports are set up correctly when issuing docker run commands.
- Python application container: 5050:5000
- Web application container: 8080:8080. Also need to change port in which Python application listens by overiding SA_LOGIC_API_URL
- Front-end: 80:80
Scaling the model with Kubernetes
Kubernetes [12] provides a way to scale an application. It also allows for zero down-time in transitioning to new/old models. Kubernetes provides an API to which users can send requests. In essense, these requests focus on defining the number of instances of a given container which need to be used. This is ideally all achieved without having to deal with hardware optimization and by Kubernetes delivering the requested number of containers of different images in an optimized way. The general structure of Kubernetes is:
- API server: providing a way to interact with operating the applications.
- Pods: similar to containers. Each one has a unique IP in the Kubernetes cluster. Communication between pods is done using this. Although pods can have multiple containers, the containers must share the same port space, volume, IP address and execution environment.
- Kubelet: providing a way to monitor the containers.
Pods: Basic commands
Pods are specified in .yaml files. These typically define kind: type of Kubernetes resource, name: resources name, image: container image, name: name of container and containerPort: port at which the container is listening. After starting Kubernetes with 'minikube start' a pod can be created using
kubectl create -f RESOURCE_NAME_pod.yaml
To verify running pods
kubectl get pods
To access the application for de-bugging purposes we can use
kubectl port-forward RESOURCE_NAME 88:80
The service resource
The service resource acts as a way to control a set of pods that provide the same functional service. However, there will typically be pods that provide different functional services. The interaction of these is controlled using Labels. Labels are assigned to all pods that a particular service is intended to target. A selector is defined in the service, detailing which labelled pods to target. Services are also defined in .yaml files. To create a service
kubectl create -f service-SERVICE_NAME.yaml
To check the state of services
kubectl get svc
For de-bugging use
minikube service SERVICE_NAME
which opens a browser pointing to the services IP. After receiving the request, the service forwards the call to a pod. The service acts as a entry point to communicate with multiple pods simultaneously using labels. The LoadBalancer service allows for automatic balancing of the load between pods. In this way the application can be scaled (using more labelled pods) and the computer systems resources used in an optimized way.
The deployment resource
The deployment resource allows for zero down-time, by automating the process of moving between application versions. They are again defined in .yaml files. Several important use cases exist:
- A change has been made to the application and needs to be implemented at scale. In order to do this the following steps would be taken:
- Create a new deployment .yaml file in which the new container image is specified. Also specify the number of instances required (replicas).
- Execute 'kubectl apply -f DEPLOYMENTFILE_NEWNAME.yaml --record
- Check status with 'kubectl rollout status deployment POD_NAME'
- Check in browser with 'minikube service SERVICE_NAME'
- Changing back to a previous version.
- Check previous versions with 'kubectl rollout history deployment POD_NAME'
- Specify version to use with 'kubectl rollout undo deployment POD_NAME --to-revision=1
Deploying the Fraud Detection API
In order to deploy the Fraud Detection API using Kubernetes several elements must be set up:
- Deployment .yaml for the front-end.
- LoadBalancer Service for the front-end to enable an entry point to the front-end pods and balance the load between them.
- Deployment .yaml for the Python application.
- Service for the Python application, again to allow there to be an entry point for these Python application pods.
- Deployment .yaml for the web application.
- LoadBalancer Service for the web application to expose the web application pods externally.
Bibliography
- R. Maloku. Learn Kubernetes in Under 3 Hours: A Detailed Guide to Orchestrating Containers, freeCodeCamp, 2018.
- R. Dahl. Node: JavaScript run time environment that executes JavaScript code outside of a browser., Node, 2009.
- I. Schlueter. npm: package manager for the JavaScript programming language., npm, 2010.
- J. Walke. React: A JavaScript library for building user interfaces, React, 2013.
- I. Sysoev. Nginx: High Performance Load Balancer, Web Server & Reverse Proxy, nginx, 2004.
- Pivotal. Spring., spring, 2002.
- Oracle. JDK8: Java SE Development Kit 8., java, 2007.
- Apache. Apache Maven., maven, 2004.
- D. Cournapeau. scikit-learn: Machine Learning in Python, Journal of Machine Learning Research, 2007.
- M. L. G. -. ULB. Credit Card Fraud Detection: Anonymized credit card transactions labeled as fraudulent or genuine, Journal of Machine Learning Research, 2018.
- S. Hykes. Docker., Docker Inc., 2013.
- J. Beda, B. Burns, C. McLuckie, B. Grant and T. Hockin. Kubernetes., Cloud Native Computing Foundation, 2014.